Metadata
- Author: Databricks
- Full Title:: Apache Spark as a Compiler: Joining a Billion Rows Per Second on a Laptop
- Category:: 🗞️Articles
- Document Tags:: Spark Spark
- URL:: https://www.databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html
- Finished date:: 2023-05-02
Highlights
Having each operator implement an iterator interface allowed query execution engines to elegantly compose arbitrary combinations of operators without having to worry about what opaque data type each operator provides. As a result, the Volcano model became the standard for database systems in the last two decades, and is also the architecture used in Spark. (View Highlight)
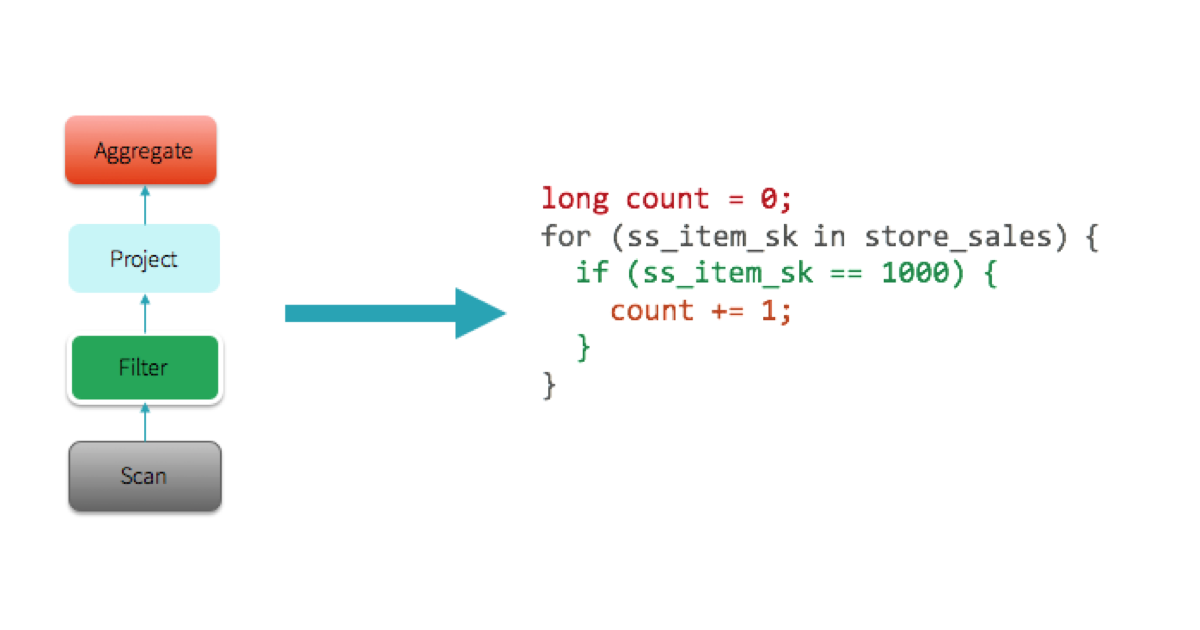
The key take-away here is that the hand-written code is written specifically to run that query and nothing else, and as a result it can take advantage of all the information that is known, leading to optimized code that eliminates virtual function dispatches, keeps intermediate data in CPU registers, and can be optimized by the underlying hardware (View Highlight)
From the above observation, a natural next step for us was to explore the possibility of automatically generating this handwritten code at runtime, which we are calling “whole-stage code generation.” This idea is inspired by Thomas Neumann’s seminal VLDB 2011 paper on Efficiently Compiling Efficient Query Plans for Modern Hardware. For more details on the paper, Adrian Colyer has coordinated with us to publish a review on The Morning Paper blog today. (View Highlight)
There are, however, cases where it is infeasible to generate code to fuse the entire query into a single function. (View Highlight)
(examples can range from calling out to Python/R to offloading computation to the GPU). (View Highlight)
For example, variable-length data types such as strings are naturally more expensive to operate on (View Highlight)
workloads that were previously I/O bound are less likely to observe gains. (View Highlight)