- Tags:: 🗣️Talks , Data Engineering
- Author:: Maxime Beauchemin
- Link:: Functional Data Engineering - A Set of Best Practices | Lyft - YouTube
- Source date:: 2018-05-28
- Finished date:: 2022-06-27
Comes with an article version: Functional Data Engineering — a modern paradigm for batch data processing | by Maxime Beauchemin | Medium
The most surprising thing of the talk is his radical approach towards Slowly Changing Dimensions: no type-2. Instead, snapshot all data! (Storage and compute is cheap. Engineering time is expensive and this is very easy to reason about)
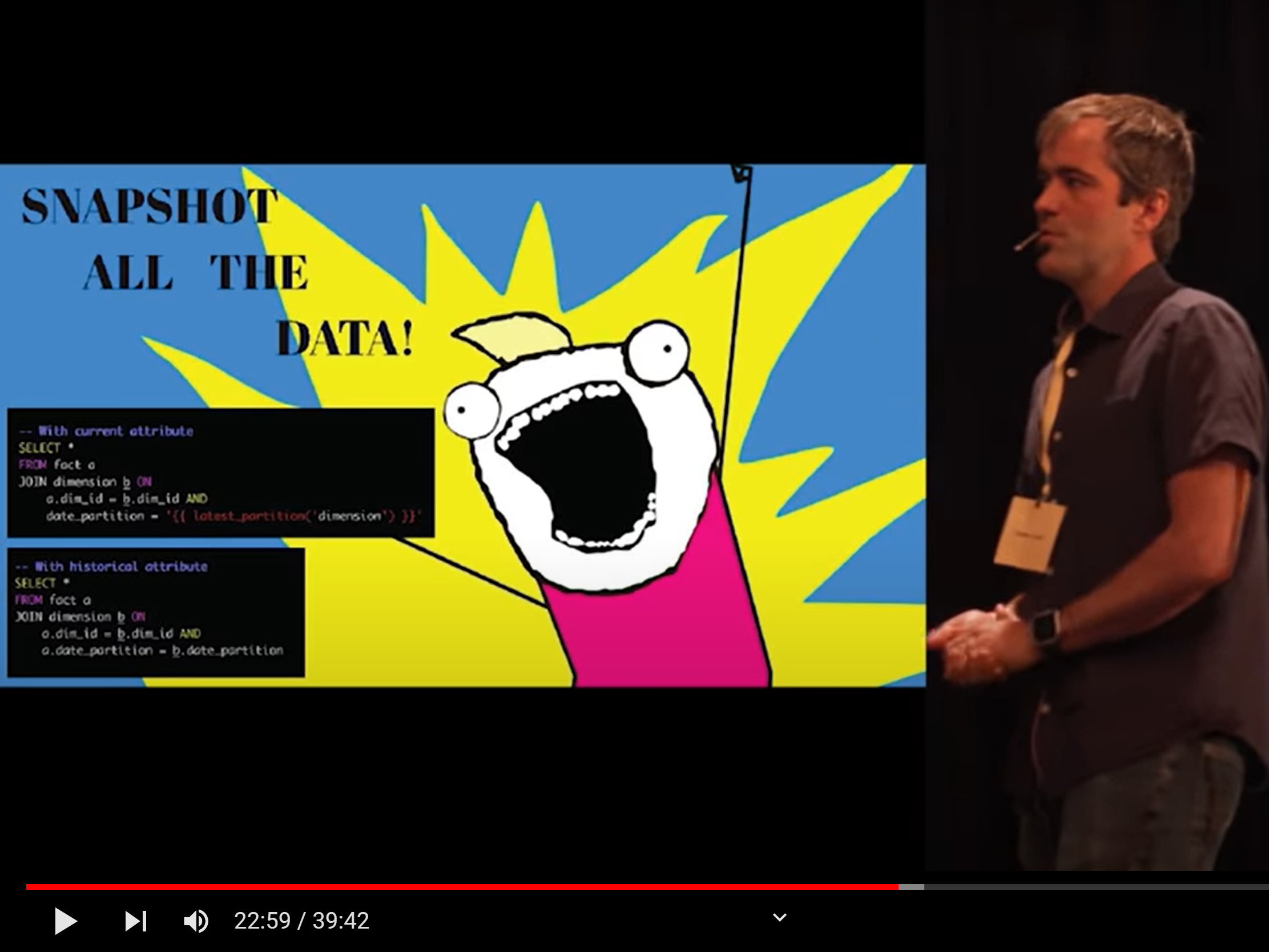
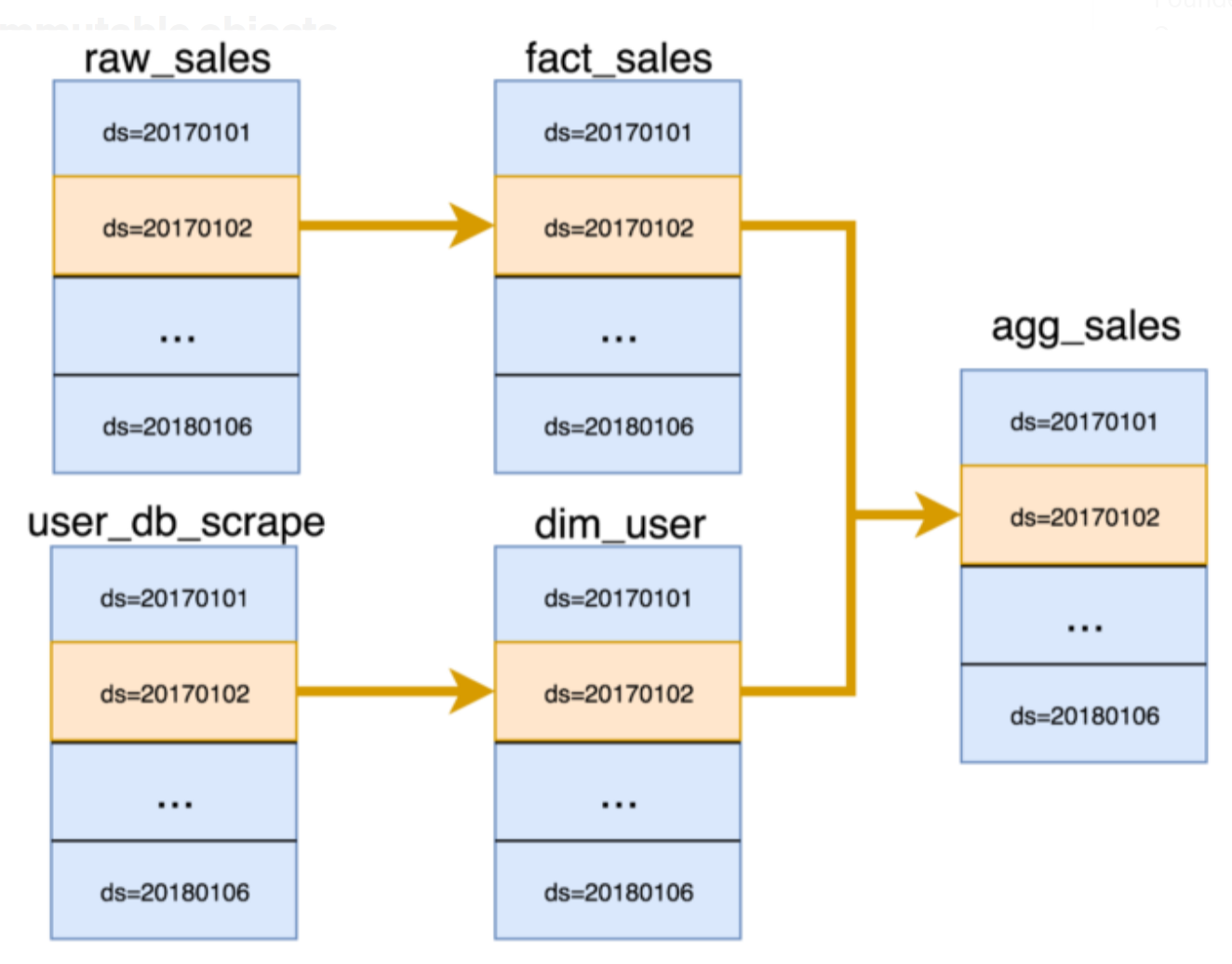
So you end up with a partition lineage:
And, in the passing, a very (IMHO) controversial statement:
you had small teams of highly specialized data professionals building the warehouse for the company. I think that’s not true anymore (…) everyone is welcome to use and create and mute and change and shape the future of the data warehouse (33:15)
Socorro, Maxime, the Tragedy Of The Commons!
Past dependencies
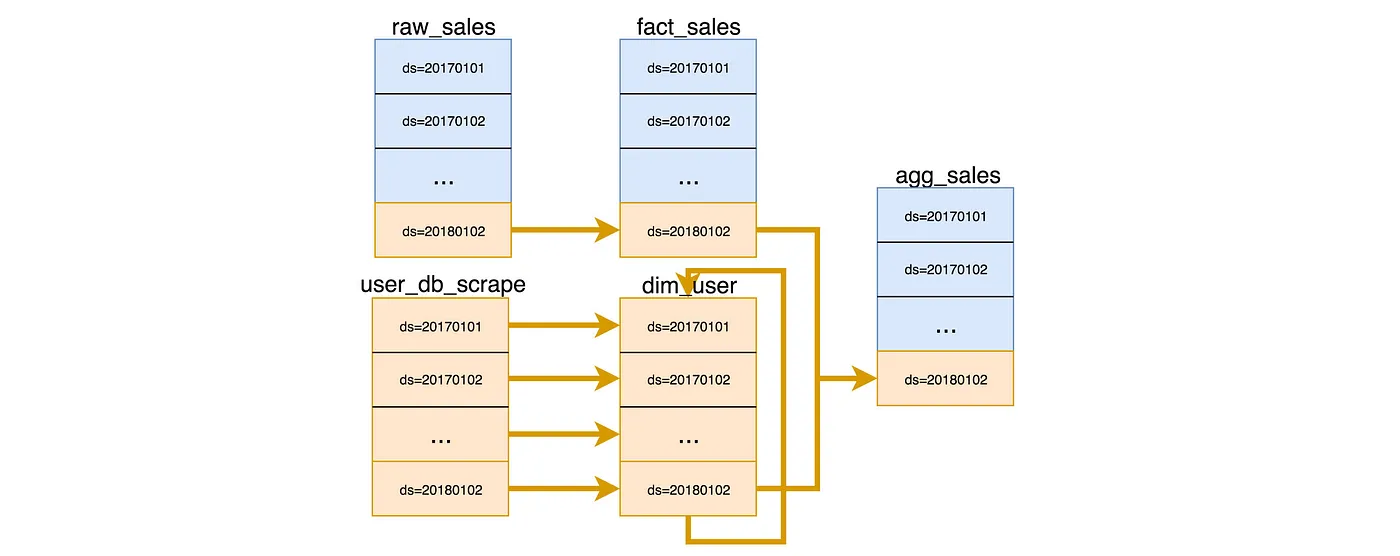
Given that backfills are common and that past dependencies lead to high-depth DAGs with limited parallelization, it’s a good practice to avoid modeling using past-dependencies whenever possible.