- Tags:: #📜Papers , Databricks, Data Storage And Processing
- Author:: Michael Armbrust, Ali Ghodsi, Reynold Xin, Matei Zaharia
- Link:: https://drive.google.com/open?id=14sbN3iXmYH5rQc1Aci_mU1KMpnG4BNDQ&authuser=mario.lopezmartinez87%40gmail.com&usp=drive_fs
- Source date:: 2021-01-01
- Finished date:: 2021-05-23
Data Warehouses are good for structured data and analytics, Data Lakes are good for unstructured data and ML, so you end up with both:
This two-tier data lake + warehouse architecture is now dominant in the industry in our experience (used at virtually all Fortune 500 enterprises).
…and the complexity of handling those two storages in sync. So, why not have your cake and eat it too? That is a Lakehouse.
This paper argues that the data warehouse architecture as we know it today will wane in the coming years and be replaced by a new architectural pattern, which we refer to as the Lakehouse, characterized by (i) open direct-access data formats, such as Apache Parquet and ORC, (ii) first-class support for machine learning and data science workloads, and (iii) state-of-the-art performance.
The improved management is implemented with a transactional metadata layer over the data files in low-cost storage, and performance optimizations are made through caching on faster storage, auxiliary data structures (indexes and stats) and data layout (e.g., ordering of records within a file, clusterization of files) similarly to warehouses.
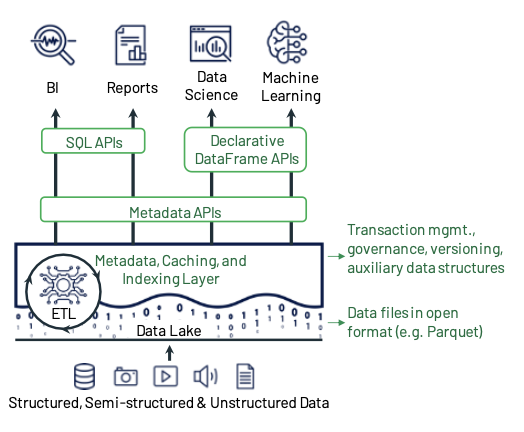
Apache Hive ACID stores metadata in an OLTP DBMS, while Delta Lake, Apache Iceberg and Apache Hudi do so directly in the data lake in Parquet. This has some limitations because of the latency in reading/writing to the layer (but simplifies design, avoiding an additional storage system).
Additionally, Databricks provides a declarative DataFrame API that allows to benefit from these optimizations (instead of directly reading the parquet files).