- Tags:: 🗞️Articles, Prophet, Forecasting
- Author:: Peter Cotton (Founder of Microprediction)
- Link:: Is Facebook’s “Prophet” the Time-Series Messiah, or Just a Very Naughty Boy? (microprediction.com)
- Source date:: 2021-02-03
- Finished date:: 2022-03-18
A literature review with no examples of Prophet making a good job
Though I’m not sure if they are fair. For example:
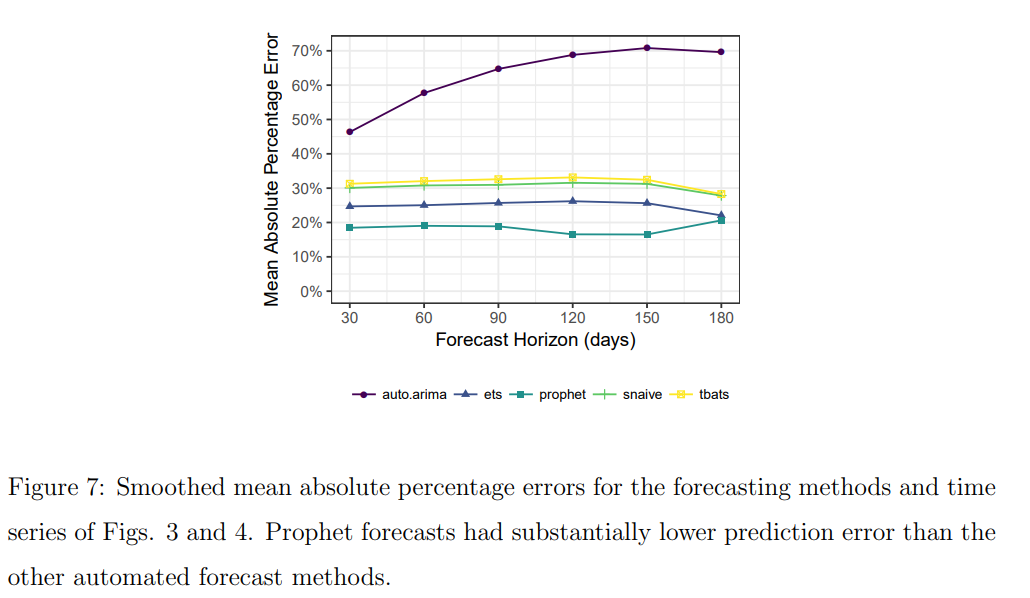
Professor Nikolaos Kourentzes benchmarked prophet against several other R packages - namely the forecast package and the smooth package which you may have used, and also mapa and thief. His results are written up in this article which uses the M3 dataset and mean absolute scaled error (link). His tone is more unsparing. “Prophet performs very poorly… my concern is not that it is not ranking first, but that at best it is almost 16% worse than exponential smoothing (and at worst almost 44%!).”
It is worth noting that the M3 competition does not feature higher frequency time series, where you would have multiple seasonalities which are not so easy to model with other techniques. But this other one does feature daily sales:
For instance a paper considering Prophet by Jung, Kim, Kwak and Park comes with the title A Worrying Analysis of Probabilistic Time-series Models for Sales Forecasting (pdf) (…) The authors list Facebook’s Prophet as the worst performing of all algorithms tested. The author’s explanation is, I think, worth reproducing in full.
The patterns of the time series are complicated and change dynamically over time, but Prophet follows such changes only with the trend changing. The seasonality prior scale is not effective, while higher trend prior scale shows better performance. There exist some seasonality patterns in the EC dataset, but these patterns are not consistent neither smooth. Since Prophet does not directly consider the recent data points unlike other models, this can severely hurts performance when prior assumptions do not fit.
The author argues that there are no comparisons by the authors of Prophet in the original paper, which is not completely true, since there is a comparison for Facebook events:
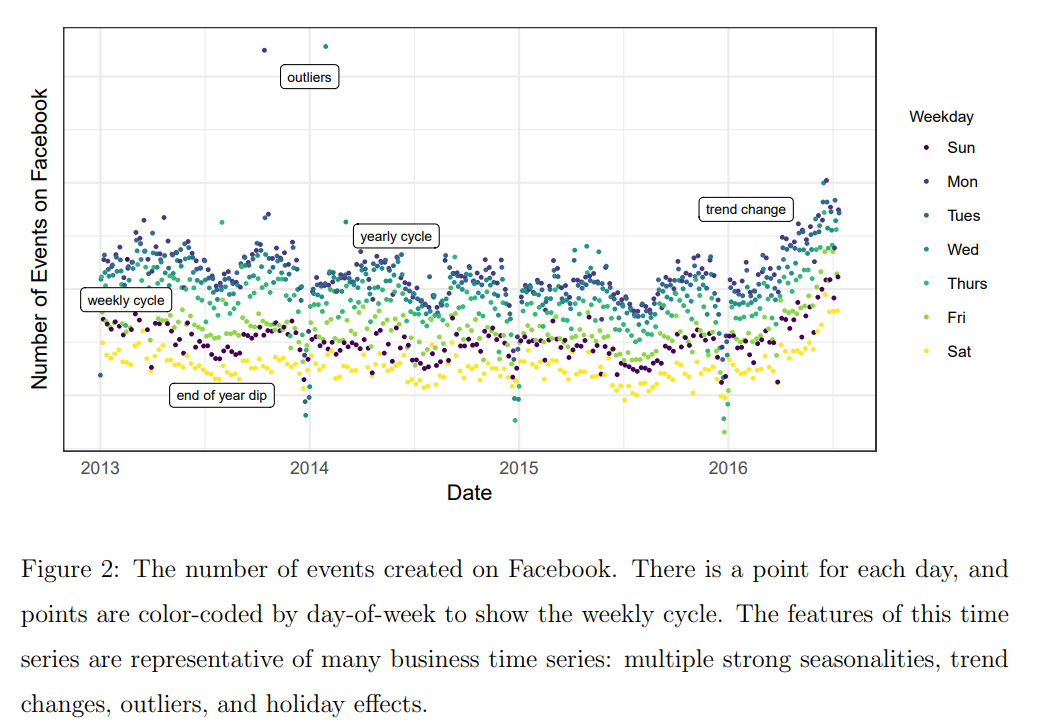
 But we cannot reproduce it (and it is just one comparison).
But we cannot reproduce it (and it is just one comparison).
The flaws of Prophet
The main critique: risky trend extrapolations
My point, to reiterate, is that Prophet is very strongly opinionated despite its use of Bayes Rule because the generative model represents a sparse set of possibilities (…) Prophet might lead you to believe that due to one particularly bad day, hospital wait times at Piedmont-Atlanta are going to trend upwards indefinitely.
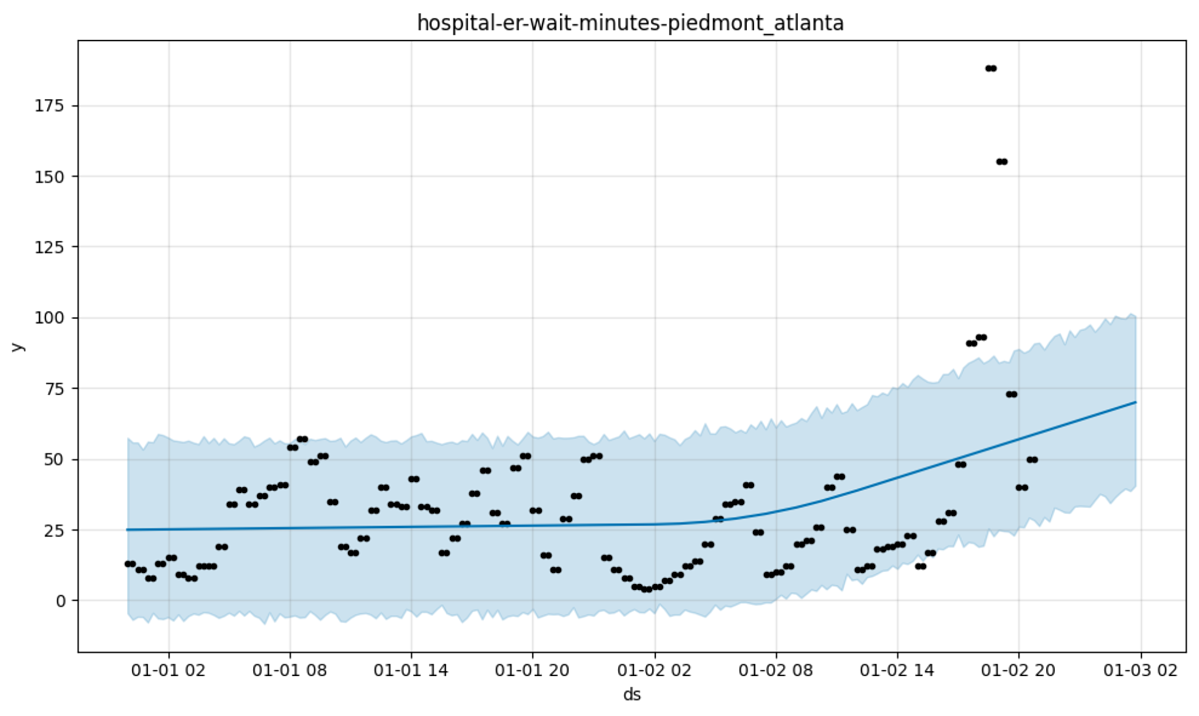
There is no dampening of the trend in Prophet, something that we know is no good. In Forecasting we can read:
The forecasts generated by Holt’s linear method display a constant trend (increasing or decreasing) indefinitely into the future. Empirical evidence indicates that these methods tend to over-forecast, especially for longer forecast horizons. Motivated by this observation, Gardner & McKenzie (1985) introduced a parameter that “dampens” the trend to a flat line some time in the future. Methods that include a damped trend have proven to be very successful, and are arguably the most popular individual methods when forecasts are required automatically for many series.
Another example:
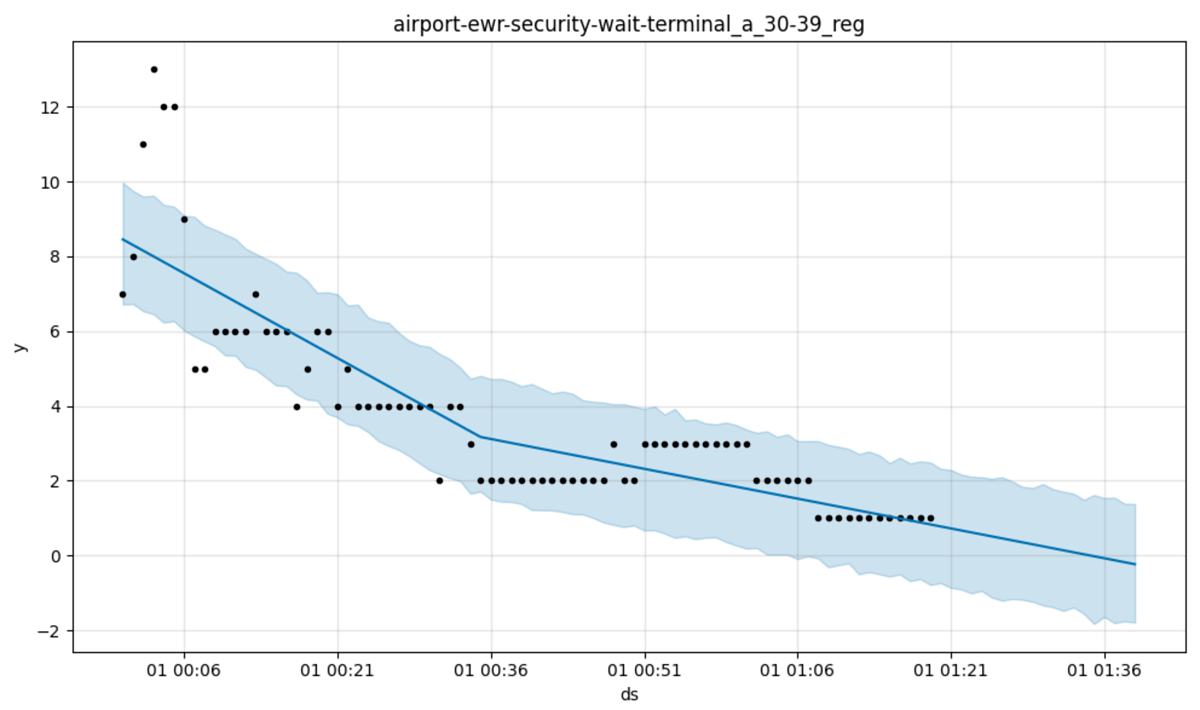
In a similar vein, do you expect the wait time at Newark Airport to go negative any time soon? Now we’re reinserting our generalized intelligence and that seems unfair but even so, if a time series has never, ever gone below a certain level, isn’t it pretty cheeky to predict that it will, with high probability, do precisely that? That might be an easy way to improve the generative model just a tad.
It is like the XKCD joke:
I wonder what would have happened had he used the logistic growth model instead, with caps.
A very simple generative model
No good with minor time misalignments
The Prophet generative model also suggests that where cycles occur which are rhythmic but not precisely so, things might go wrong.
No good with bursts / changepoints
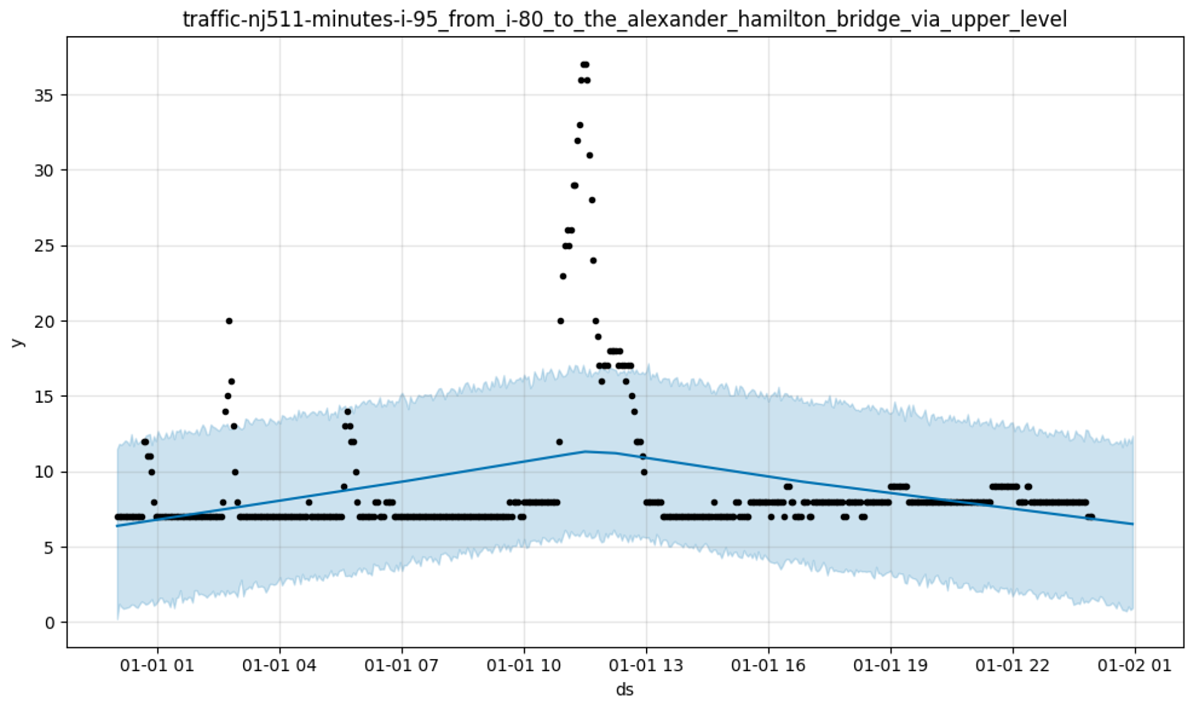
By design, Prophet’s generative model might treat all manner of disturbances as noise, no matter how prolonged they are or whether they are the dominant feature of the data.
anyone looking to use the software will understand that this is, at heart, a low pass filter.
Just imagine how bad the out-of-sample performance of this model is going to be compared to, say, an ARIMA with change-point detection or even a Kalman filter.
This, according to the author, is something we would see in sales:
a pronounced change-point that should, I would think, be quite similar to a change in a product you’d see in those sales time series where Prophet (we are told) excels.
A quick fix to Prophet overconfidence
Motivated by these examples, here’s a really simple hack that seems to improve prophet
- Look at the last five data points, and compute their standard deviation.
- Construct an upper bound by adding m standard deviations to the highest data point, plus a constant. Similarly for a lower bound.
- If Prophet’s prediction is outside these bounds, use an average of the last three data points instead.
As elementary as this sounds, it really works - even when forecasting way ahead. For example, when selecting random time series from this list, giving Prophet 500 points to train on, and requesting a prediction 50 steps ahead, this simple heuristic with m=3 decreased the root mean square error by a whopping 25%
But it is still disappointing:
In keeping with some of the cited work, I find that Prophet is beaten by exponential moving averages at every horizon thus far (ranging from 1 step ahead to 34 steps ahead when trained on 400 historical data points). More worrying, the moving average models don’t calibrate. I simply hard wired two choices of parameter.
Unfortunately, even Sean J Taylor, one of Prophet creators, agrees with most of this evaluation: Thread by @seanjtaylor on Thread Reader App – Thread Reader App