Metadata
- Author: Alban Perillat Merceroz
- Full Title:: Give Meaning to 100 Billion Analytics Events a Day
- Category:: 🗞️Articles
- Document Tags:: Adtech Data Lake Alternatives
- URL:: https://medium.com/teads-engineering/give-meaning-to-100-billion-analytics-events-a-day-d6ba09aa8f44
- Finished date:: 2023-04-15
Highlights
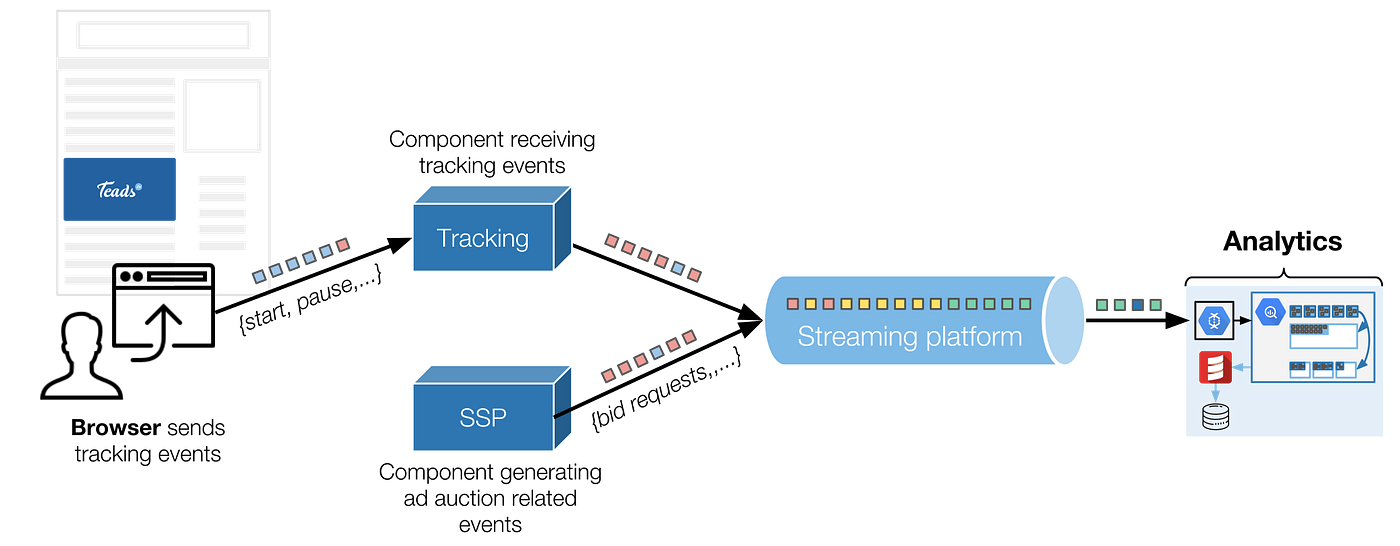 (
(Analytics team whose mission is to take care of these events (View Highlight)
We ingest the growing amount of logs, We transform them into business-oriented data, Which we serve efficiently and tailored for each audience. (View Highlight)
We considered several promising alternatives like Druid and BigQuery. We finally chose to migrate to BigQuery because of its great set of features. (View Highlight)
With BigQuery we are able to: • Work with raw events, • Use SQL as an efficient data processing language, • Use BigQuery as the processing engine, • Make explanatory access to data easier (compared to Spark SQL or Hive), (View Highlight)
We considered several promising alternatives like Druid and BigQuery. We finally chose to migrate to BigQuery because of its great set of features. With BigQuery we are able to: • Work with raw events, • Use SQL as an efficient data processing language, • Use BigQuery as the processing engine, • Make explanatory access to data easier (compared to Spark SQL or Hive), (View Highlight)
Thanks to a flat-rate plan, our intensive usage (query and storage-wise) is cost efficient. (View Highlight)
We were sold on Dataflow’s promises and candidly tried streaming mode. Unfortunately, after opening it to real production traffic, we had an unpleasant surprise: BigQuery’s streaming insertion costs. (View Highlight)
We also faced other limitations like the 100,000 events/s rate limit, which was dangerously close to what we were doing. (View Highlight)
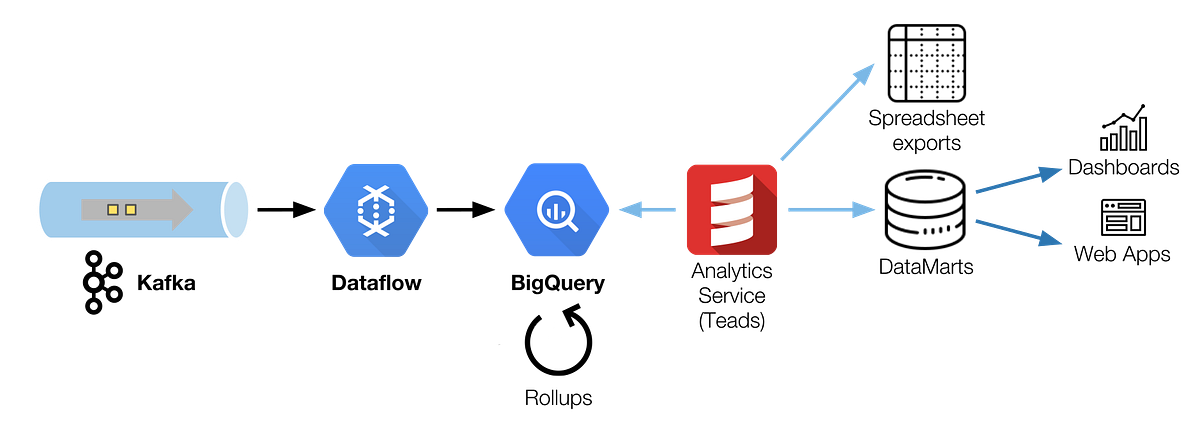
Our resulting architecture is a chain of 30 min Dataflow batch jobs, sequentially scheduled to read a Kafka topic and write to BigQuery using load jobs. (View Highlight)
For efficient parallelism you should always try to keep a number of CPU threads that is a divisor of the number of partitions you have (corollary: it’s nice to have a number of Kafka partitions that is a highly composite number). (View Highlight)
Raw data is inevitably bulky, we have too many events and cannot query them as is. We need to aggregate this raw data to keep a low read time and compact volumes (View Highlight)
we choose to store it first (ELT), in a raw format. It has two main benefits: • It lets us have access to each and every raw event for fine analysis and debug purposes, • It simplifies the entire chain by letting BigQuery do the transformations with a simple but powerful SQL dialect. (View Highlight)
the raw events table directly is nice for debugging and deep analysis purposes, but it’s impossible to achieve acceptable performance querying a table of this scale, not to mention the cost of such operation. To give you an idea, this table has a retention of 4 months only, contains 1 trillion events, for a size close to 250TB. (View Highlight)
query runtime isn’t much impacted, the improvement is measured on the number of slots used. (View Highlight)
This is no longer true
BigQuery doesn’t support column drop (View Highlight)