Metadata
- Author: Imply
- Full Title:: Druid Architecture & Concepts
- Category:: 🗞️Articles
- URL:: https://imply.io/druid-architecture-concepts/
- Finished date:: 2023-04-03
Highlights
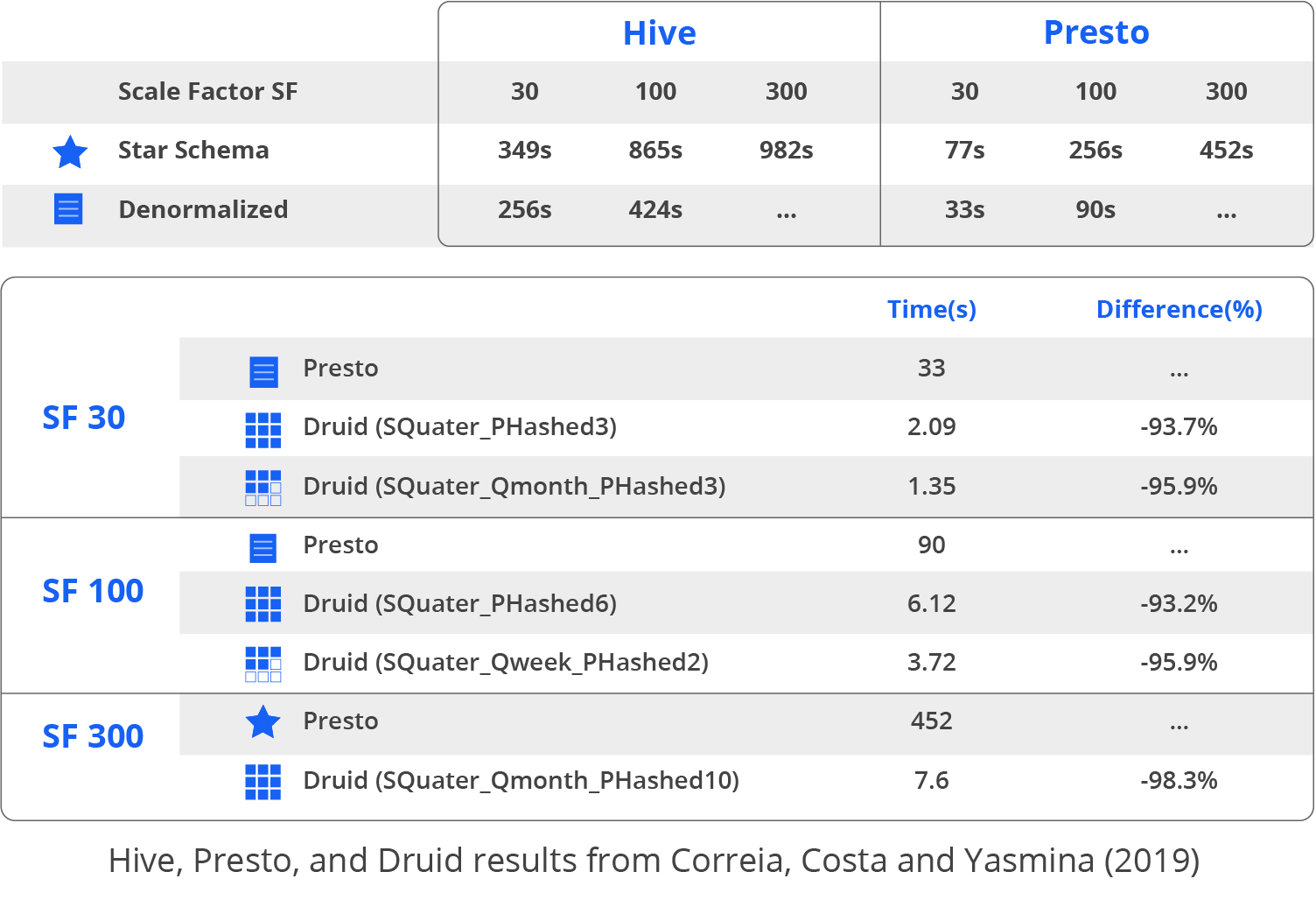
In 2011, the data team at a technology company had a problem. They needed to quickly aggregate and query real-time data coming from website users across the Internet to analyze digital advertising auctions. This created large data sets, with millions or billions of rows. They first implemented their product using relational databases, starting with Greenplum, a fork of PostgreSQL. It worked, but needed many more machines to scale, and that was too expensive. They then used the NoSQL database HBase populated from Hadoop Mapreduce jobs. These jobs took hours to build the aggregations necessary for the product. At one point, adding only 3 dimensions on a data set that numbered in the low millions took the processing time from 9 hours to 24 hours.. So, in the words of Eric Tschetter, one of Druid’s creators, “we did something crazy: we rolled our own database!” (View Highlight)
Druid gets both performance and cost advantages by storing the segments on cloud storage and also pre-fetching them so they are ready when requested by the query engine. (View Highlight)