
Metadata
- Author: Piotr Migdał
- Full Title:: Don’t Use Cosine Similarity Carelessly
- Category:: 🗞️Articles
- Document Tags:: Rag,
- URL:: https://p.migdal.pl/blog/2025/01/dont-use-cosine-similarity
- Read date:: 2025-01-23
Highlights
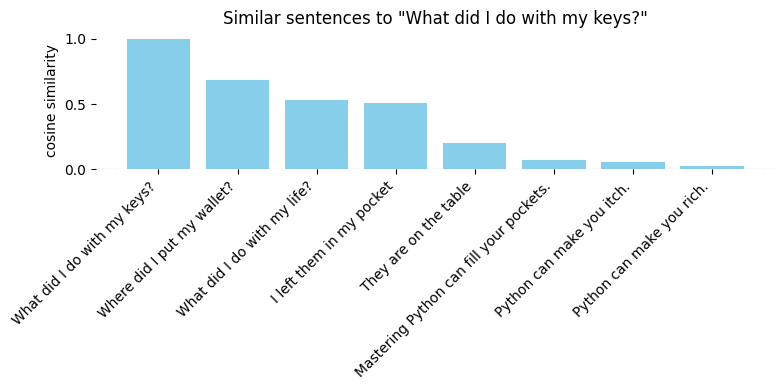
While embeddings do capture similarities, they often reflect the wrong kind - matching questions to questions rather than questions to answers, or getting distracted by superficial patterns like writing style and typos rather than meaning. (View Highlight)
Just because the values usually fall between 0 and 1 doesn’t mean they represent probabilities or any other meaningful metric. The value 0.6 tells little if we have something really similar, or not so much. And while negative values are possible, they rarely indicate semantic opposites — more often, the opposite of something is gibberish. (View Highlight)
 (
(The trouble begins when we venture beyond its comfort zone, specifically when: • The cost function used in model training isn’t cosine similarity (usually it is the case!). • The training objective differs from what we actually care about. (View Highlight)
even if a model is explicitly trained on cosine similarity, we run into a deeper question: whose definition of similarity are we using? (View Highlight)
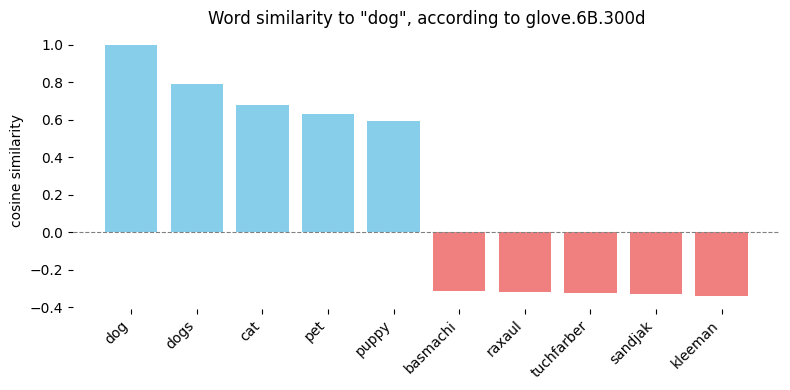
In the US, word2vec might tell you espresso and cappuccino are practically identical. It is not a claim you would make in Italy. (View Highlight)
 (
(The best approach is to directly use LLM query to compare two entries. (View Highlight)
instead of blindly trusting a black box, we can directly optimize for what we actually care about by creating task-specific embeddings. There are two main approaches: • Fine-tuning (teaching an old model new tricks by adjusting its weights). • Transfer learning (using the model’s knowledge to create new, more focused embeddings). (View Highlight)
One of the quickest fixes is to add prompt to the text, so to set the apparent context. (View Highlight)
Another approach is to preprocess the text before embedding it. Here’s a generic trick I often use — I ask the model:
“Rewrite the following text in standard English using Markdown. Focus on content, ignore style. Limit to 200 words.” (View Highlight)