a data quality specification for a dataset that describes
• schema of the dataset
• simple column-oriented quality rules (is_not_null, values_between etc.)
anchored around a dataset which is typically a physical event stream produced by a team / domain
3️. also a carrier for semantic aka business metadata
• ownership
• classification tags
4️. can also describe operational SLO-s
• freshness goals (e.g. must be available for processing by 7am in the warehouse)
5️. can also be a specifier for provisioning configuration for a dataset (e.g. provision this dataset on Kafka and BigQuery) (View Highlight)
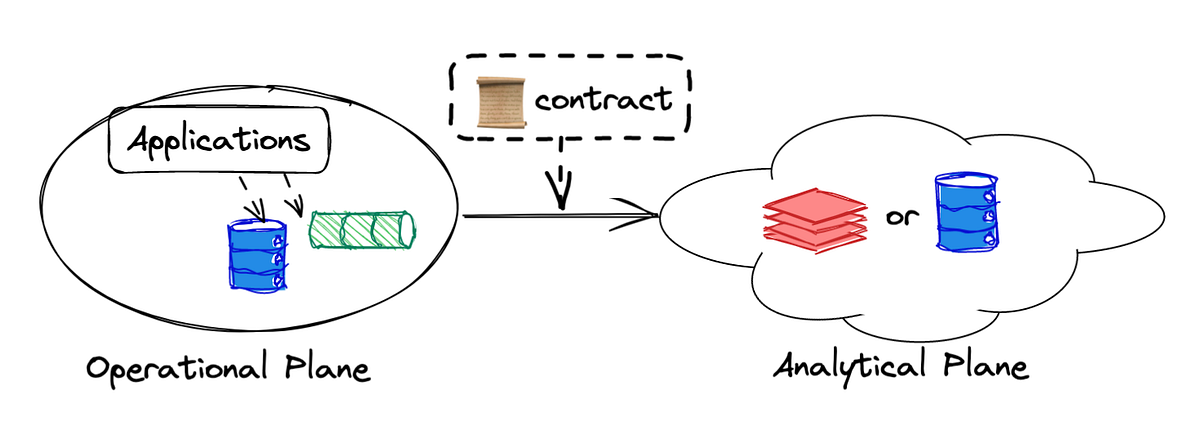
whether there is a specific reason the community is hyper-focused on attaching data contracts only to this edge. One of the reasons this has happened is that a lot of the intention behind the conversation around data contracts is to shift responsibility and accountability for data to the application teams that produce it (View Highlight)
Use a git-based process for creating and managing the lifecycle of a data contract (View Highlight)