
Metadata
- Author: Dbt Labs
- Full Title:: Centralized vs decentralized data teams
- Category:: 🗞️Articles
- Document Tags:: Data Team Topologies, Data Team Topologies,
- URL:: https://www.getdbt.com/data-teams/centralized-vs-decentralized/
- Finished date:: 2023-06-27
Highlights
they have tried five different data team structures over the course of nine months. This is a legitimately difficult problem (View Highlight)
Ten years ago, the most challenging problem a data team faced was managing compute and store resources (View Highlight)
data analysts had no choice but to request changes to the data warehouse and patiently wait for the data engineers to deliver (View Highlight)
The biggest challenges today are around speed: How can we help data engineers and analysts collaborate more effectively? (View Highlight)
In the decentralized model, you’ll typically see a central core group of data engineers who own the data warehouse with analysts being decentralized, or embedded, within a business function such as finance or product. (View Highlight)
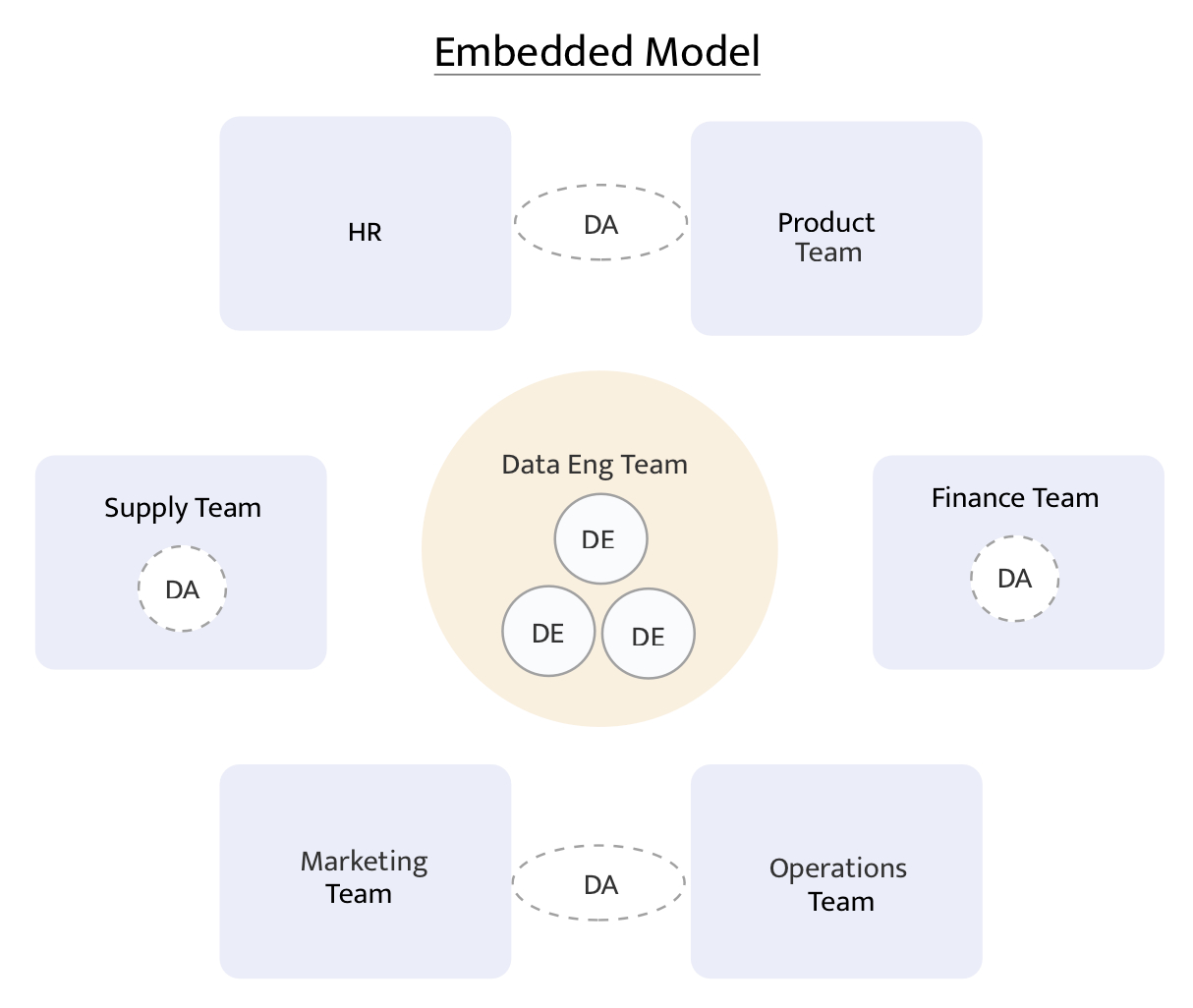 (
(However, what we see is that this speed is highly dependent on just how empowered analysts are. If analysts are empowered to own the analytics engineering workflow, this model can work quite well (see examples from JetBlue and HubSpot). If analysts in a decentralized model spend most of their time in the BI tool and rely on data engineers for data transformation and modeling work, then analytics velocity will slow as analysts wait in the data engineering queue. (View Highlight)
Ultimately they landed where we see more and more companies land – a hybrid version (View Highlight)
Their full-stack team quickly grew from eight team members to 12 in March 2020, and team meetings became a waste of time for most members, because only one or two people were needed to make a decision. Their solution to this problem was to create multiple pods that specifically owned a full-stack problem in a given area of the business. (View Highlight)