## Metadata
- Author: [[Ethan Ding]]
- Full Title:: Tokens Are Getting More Expensive
- Category:: #🗞️Articles
- URL:: https://ethanding.substack.com/p/ai-subscriptions-get-short-squeezed?utm_campaign=posts-open-in-app&triedRedirect=true
- Read date:: [[2025-08-31]]
## Highlights
>  ([View Highlight](https://read.readwise.io/read/01k3znkfa6f9ad99z1gryntsbd))
>  ([View Highlight](https://read.readwise.io/read/01k3znkfdfksmr2d96gp16xvgp))
> when a new model is released as the SOTA, 99% of the demand immediatley shifts over to it. consumers expect this of their products as well.
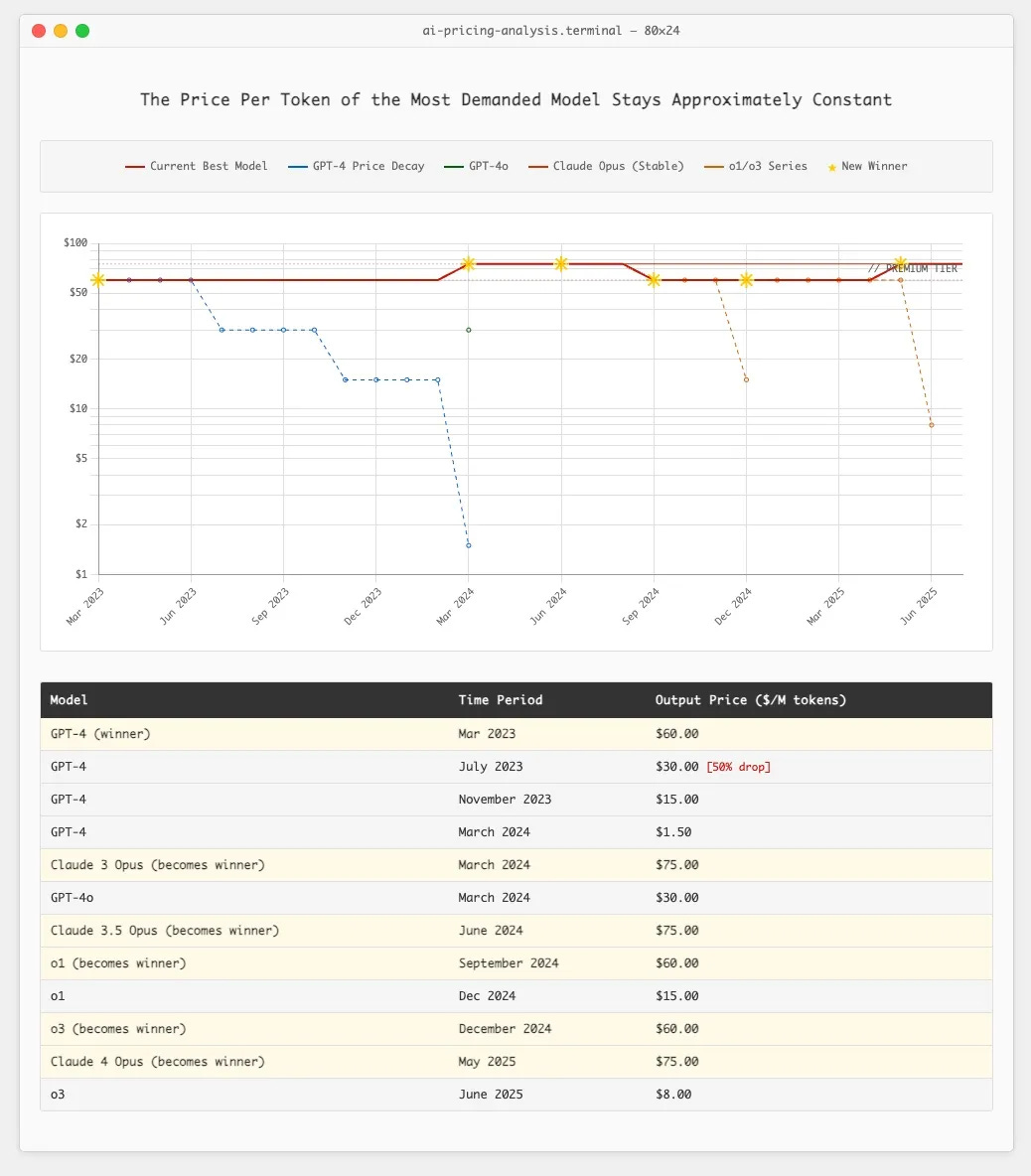
> now look at the actual pricing history of frontier models, the ones that 99% of the demand is for at any given time: ([View Highlight](https://read.readwise.io/read/01k3znke4jbmebvhf0nww37js9))
> the math gets genuinely insane when you extrapolate:
> today, a 20-minute "deep research" run costs about $1. by 2027, we'll have agents that can run for 24 hours straight without losing the plot… combine that with the static price of the frontier? that’s a ~$72 run. per day. per user. with the ability to run multiple asynchronously.
> once we can deploy agents to run workloads for 24 hours asynchronously, we won't be giving them one instruction and waiting for feedback. we'll be scheduling them in batches. entire fleets of ai workers, attacking problems in parallel, burning tokens like it's 1999. ([View Highlight](https://read.readwise.io/read/01k3znptfkj6fn76x9rbhzn85e))
But on VLMs we don't have these feedback loops: it's not arbitrary work, it's creative and humans will always want to be on the loop.
> the lesson isn't that they didn't charge enough, it’s that there’s no way to offer unlimited usage in this new world under any subscription model. ([View Highlight](https://read.readwise.io/read/01k3znvn66j68129x64h0k25jr))
> there are three ways out:
> **1. usage-based pricing from day one**
> no subsidies. no "acquire now, monetize later." just honest economics. sounds great in theory.
> except show me the consumer usage-based ai company that's exploding. consumers hate metered billing. they'd rather overpay for unlimited than get surprised by a bill. ([View Highlight](https://read.readwise.io/read/01k3zp21kv57xqkj30zevxnjx4))
> 2. insane switching costs ⇒ high margins ([View Highlight](https://read.readwise.io/read/01k3zp3fbjktenvkpvmntkpcdt))
> would you rather have $10M of ARR from goldman sachs or $500m from prosumer devleopers? ([View Highlight](https://read.readwise.io/read/01k3zp3r9ff5250y533xbcazd5))
> **3. vertical integration ⇒ make money on the infra**
> this is replit’s game: bundle the coding agent with your application hosting, database management, deployment monitoring, logging, etc. lose money on every token, but capture value at every single other layer of the stack for this new generation of developers ([View Highlight](https://read.readwise.io/read/01k3zp44dkdq99psdvnybv9zcm))
## New highlights added [[2025-08-31]]
> you're not selling inference. you're selling everything else, and inference is just marketing spend. ([View Highlight](https://read.readwise.io/read/01k3zvhvexvw56j1dj76hhq0nk))