## New highlights added [[2023-11-29]]
> n ([View Highlight](https://read.readwise.io/read/01hgde6vca27ba8qfdb9hfsw7y))
## New highlights added [[2024-03-11]]
Hyper Log Log. What are they based on
> Some databases have implemented approximate versions of the functions that are faster to compute and generally return high-quality results if absolute precision is not required ([View Highlight](https://read.readwise.io/read/01hrn5h2rph1mqx3vdsmqbqnaa))
Whenever we make a query, we must perform sanity checks
> Profiling: Data Quality ([View Highlight](https://read.readwise.io/read/01hrn5kv0sg94rpnrdes5s0kz8))
This is the easiest way
> As an alternative to a subquery, you can use a HAVING clause and keep everything in a single main query. Since it is evaluated after the aggregation and GROUP BY, HAVING ([View Highlight](https://read.readwise.io/read/01hrn642n3rqqwwqgr0j4pres3))
But please check why so we having duplicates
> One way to remove duplicates is to use the keyword DISTINCT ([View Highlight](https://read.readwise.io/read/01hrn6awzrkmwvy9pd1wbj9f7v))
## New highlights added [[2024-03-10]]
> data munging, data wrangling, and data prep. (“Mung” is an acronym for Mash Until No Good, which I have certainly done on occasion.) ([View Highlight](https://read.readwise.io/read/01hrn4nyvqm6psmd22t6kdn1dr))
If we can, we better do this step on BI
> This can’t be solved with a simple query; it requires an intermediate aggregation step, which can be accomplished with a subquery. ([View Highlight](https://read.readwise.io/read/01hrn50wtyjvbsf3744sq5e0np))
## New highlights added [[2024-03-13]]
> w ([View Highlight](https://read.readwise.io/read/01hrv60p2btc4xkfmnzgd6qche))
## New highlights added [[2024-03-15]]
> e ([View Highlight](https://read.readwise.io/read/01hrymf4mz08m3gv6jttnyqsyx))
## New highlights added [[2024-03-19]]
> b.user_id ([View Highlight](https://read.readwise.io/read/01hsatpeqap560vfph4w2nnv63))
> a.user_id ([View Highlight](https://read.readwise.io/read/01hsatpbm7exy2ayxre8gvzhk9))
> Consider including time boxes, to only include users who complete an action within a specific time frame, if users can reenter the funnel after a lengthy absence ([View Highlight](https://read.readwise.io/read/01hsatqgrsd7j8jchjm0xxd0qk))
## New highlights added [[2024-05-21]]
> t ([View Highlight](https://read.readwise.io/read/01hydchgdqgh8seggqx1tnzer0))
> t ([View Highlight](https://read.readwise.io/read/01hydckqad4zhj2pm1w2bx86a0))
Ver y recordar el caso de null.
> Cleaning Data with CASE Transformations ([View Highlight](https://read.readwise.io/read/01hydcmazebs1ec3whay0w7ff0))
> A concept related to but slightly different from nulls is empty string ([View Highlight](https://read.readwise.io/read/01hydcntece197xsxgkqkypjat))
> For example, we might expect that each customer in the transactions table also has a record in the customer table. To check this, query the tables using a LEFT JOIN and add a WHERE condition to find the customers that do not exist in the second table: SELECT distinct a.customer_id FROM transactions a LEFT JOIN customers b on a.customer_id = b.customer_id WHERE b.customer_id is null ([View Highlight](https://read.readwise.io/read/01hydcqca7avrnfem2hm09dtt8))
Explain the case of BI tools (particularly Hex)
> For Which Output: BI, Visualization, Statistics, ML ([View Highlight](https://read.readwise.io/read/01hydkhftadsn13gm2ptc3kcpa))
To avoid this we need to use Jinja or Python
> Although this syntax is more compact than the CASE construction we saw earlier, the desired columns still need to be specified. ([View Highlight](https://read.readwise.io/read/01hydm2yntjage77zm21c5svtw))
## New highlights added [[2024-06-19]]
> Generally, the output for modeling will fol‐ low the notion of “tidy data” proposed by Hadley Wickham.2 ([View Highlight](https://read.readwise.io/read/01j0qgkvgnv9eakxv58br2bgzr))
## New highlights added [[2025-04-04]]
> Indexing to See Percent Change over Time ([View Highlight](https://read.readwise.io/read/01jqytstb267jhxvkf4wf1gcyw))
> 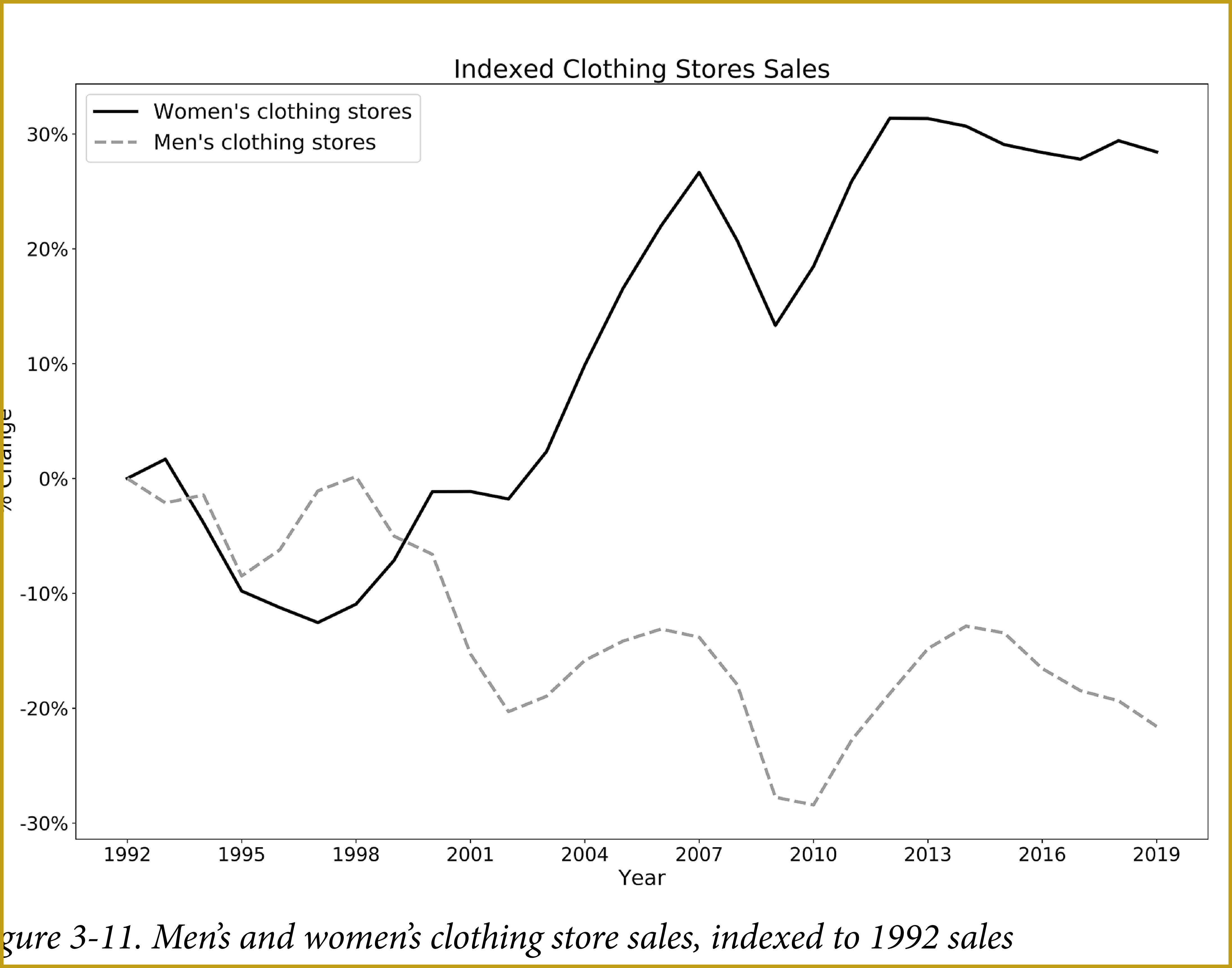 ([View Highlight](https://read.readwise.io/read/01jqytta4v5sn9vfg8qs38m0tf))
> retention in the starting period is always 100%. Over time, retention based on counts generally declines and can never exceed 100%, whereas money- or action-based retention, while often declining, can increase and be greater than 100% in a time period. ([View Highlight](https://read.readwise.io/read/01jqyv4qkp893frmtp5jh4xxeh))