## Metadata
- Author: [[Allen downey|Allen Downey]]
- Full Title:: Small Percentiles and Missing Data
- Category:: #🗞️Articles
- Document Tags:: [[Hypothesis testing|Hypothesis Testing]],
- URL:: https://allendowney.substack.com/p/small-percentiles-and-missing-data
- Finished date:: [[2024-04-29]]
## Highlights
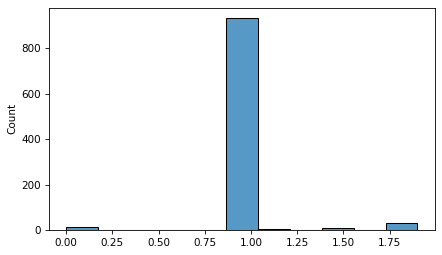
> Immediately we can see that something has gone wrong. The resampling process produces only 8 unique values. ([View Highlight](https://read.readwise.io/read/01hwnbhj9jhe6wq41sdb1z1h87))
> This example demonstrates a limitation of bootstrap resampling — it does not work well when there are a small number of unique values. ([View Highlight](https://read.readwise.io/read/01hwnbhr2jbjbgn22yx4np10bx))
> On a linear scale, it seemed like the normal model might be good enough; on a log scale, it is clear that the data deviate from the model in the left tail. ([View Highlight](https://read.readwise.io/read/01hwnbkar220wkxn7hkr4m4vcp))
> kernel density estimation (KDE) to model the distribution of the data, then use the model to resample ([View Highlight](https://read.readwise.io/read/01hwnbm6sggd4ktybsk0nk8jc2))