## Metadata
- Author: [[alban-perillat-merceroz|Alban Perillat Merceroz]]
- Full Title:: Give Meaning to 100 Billion Analytics Events a Day
- Category:: #🗞️Articles
- Document Tags:: [[adtech|Adtech]] [[data-lake-alternatives|Data Lake Alternatives]]
- URL:: https://medium.com/teads-engineering/give-meaning-to-100-billion-analytics-events-a-day-d6ba09aa8f44
- Finished date:: [[2023-04-15]]
## Highlights
>  ([View Highlight](https://read.readwise.io/read/01gy2k99ntyczwzdfk7e5zswek))
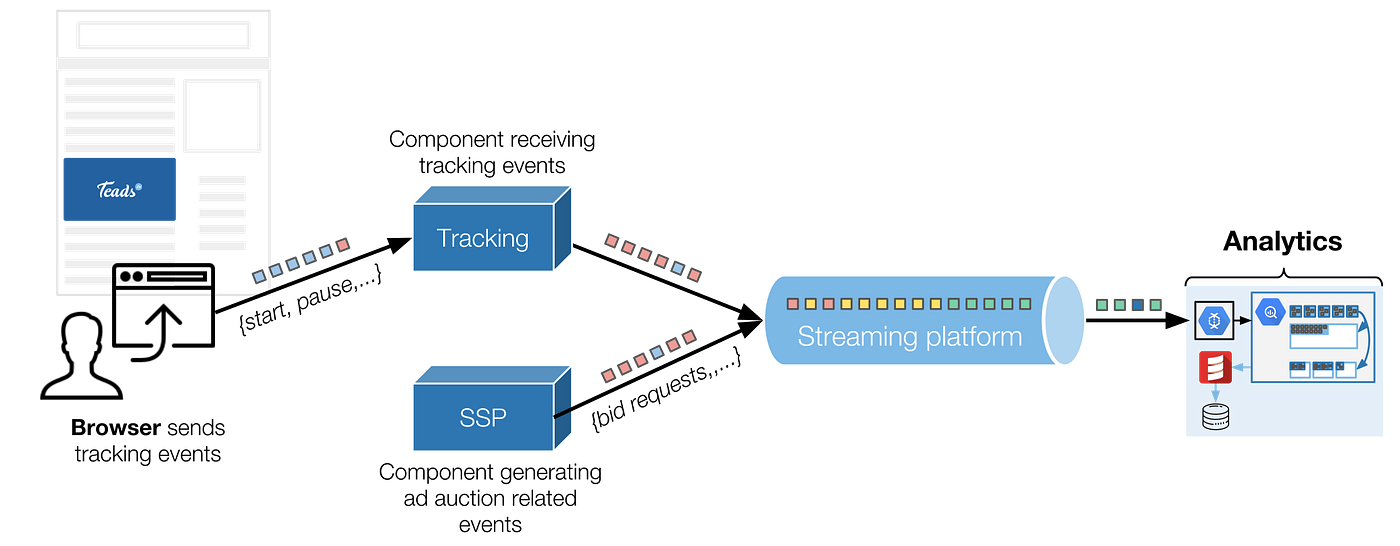
> **Analytics team** whose mission is to take care of these events ([View Highlight](https://read.readwise.io/read/01gy2jw21cjwmw2f49aq5zbphz))
> ***We ingest the growing amount of logs,***
> ***We transform them into business-oriented data,***
> ***Which we serve efficiently and tailored for each audience.*** ([View Highlight](https://read.readwise.io/read/01gy2jvygasp4hm9njm1hmmap9))
> We considered several promising alternatives like [Druid](http://druid.io/druid.html) and [BigQuery](https://cloud.google.com/bigquery/). We finally **chose to migrate to BigQuery** because of its great set of features. ([View Highlight](https://read.readwise.io/read/01gy2ka9wc57z1jew6z509q6pj))
> With BigQuery we are able to:
> • Work with raw events,
> • Use SQL as an efficient data processing language,
> • Use BigQuery as the processing engine,
> • Make explanatory access to data easier (compared to Spark SQL or Hive), ([View Highlight](https://read.readwise.io/read/01gy2ka743g4cp1w97nsgpfj5h))
> We considered several promising alternatives like [Druid](http://druid.io/druid.html) and [BigQuery](https://cloud.google.com/bigquery/). We finally **chose to migrate to BigQuery** because of its great set of features.
> With BigQuery we are able to:
> • Work with raw events,
> • Use SQL as an efficient data processing language,
> • Use BigQuery as the processing engine,
> • Make explanatory access to data easier (compared to Spark SQL or Hive), ([View Highlight](https://read.readwise.io/read/01gy2jx44rb7qr5c2ndhn7sp0t))
> **Thanks to a** [**flat-rate plan**](https://cloud.google.com/bigquery/pricing#flat_rate_pricing), our intensive usage (query and storage-wise) is cost efficient. ([View Highlight](https://read.readwise.io/read/01gy2jx9cj5csr5rpksq2n6pxk))
> We were sold on Dataflow’s promises and candidly tried streaming mode. Unfortunately, after opening it to real production traffic, we had an unpleasant surprise: **BigQuery’s streaming insertion costs**. ([View Highlight](https://read.readwise.io/read/01gy2kbzta9rw5r6rragvypram))
> We also faced other limitations like the [100,000 events/s rate limit](https://cloud.google.com/bigquery/quotas#streaminginserts), which was dangerously close to what we were doing. ([View Highlight](https://read.readwise.io/read/01gy2kd6fwn8aa5vrpxbbn4ryb))
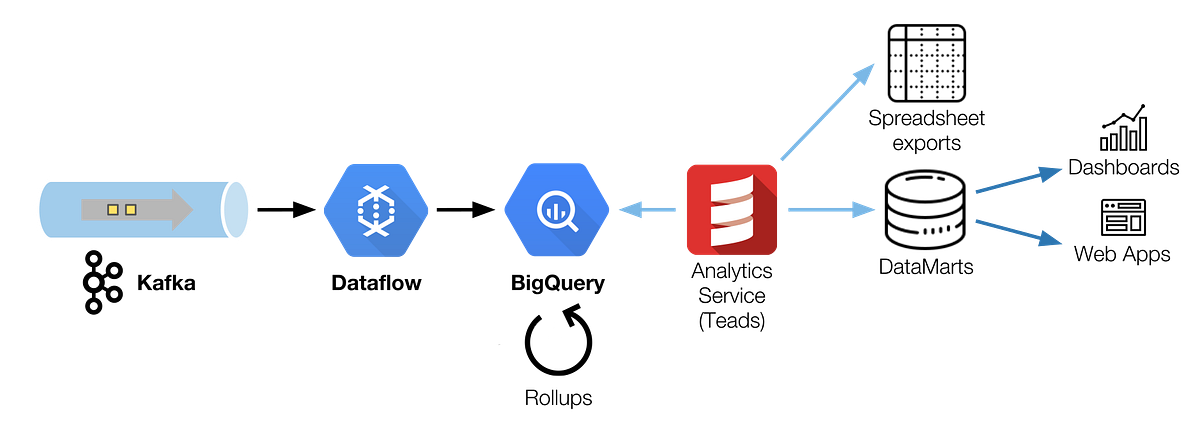
> Our resulting architecture is a chain of 30 min Dataflow batch jobs, sequentially scheduled to read a Kafka topic and write to BigQuery using load jobs. ([View Highlight](https://read.readwise.io/read/01gy2kemyrj1s8wcbkz416v199))
> For efficient parallelism you should always try to **keep a number of CPU threads that is a divisor of the number of partitions** you have (corollary: it’s nice to have a number of Kafka partitions that is a [highly composite number](https://en.wikipedia.org/wiki/Highly_composite_number)). ([View Highlight](https://read.readwise.io/read/01gy2khq3z1r433v8qhgk5kxep))
> Raw data is inevitably bulky, we have too many events and cannot query them as is. We need to aggregate this raw data to keep a low *read* time and compact volumes ([View Highlight](https://read.readwise.io/read/01gy2kpm0jd1tatt434wm004h6))
> **we choose to store it first (ELT)**, in a raw format.
> It has two main benefits:
> • It lets us have access to each and every raw event for fine analysis and debug purposes,
> • It simplifies the entire chain by letting BigQuery do the transformations with a simple but powerful SQL dialect. ([View Highlight](https://read.readwise.io/read/01gy2kq8b01rnej14kr8nfx7fm))
> the raw events table directly is nice for debugging and deep analysis purposes, but it’s impossible to achieve acceptable performance querying a table of this scale, not to mention the [cost](https://cloud.google.com/bigquery/pricing) of such operation.
> To give you an idea, this table has a retention of 4 months only, contains **1 trillion events, for a size close to 250TB**. ([View Highlight](https://read.readwise.io/read/01gy2kwnqf67vznsxb8e6b87xv))
> query runtime isn’t much impacted, the improvement is measured on the number of slots used. ([View Highlight](https://read.readwise.io/read/01gy2kxfwg4ckysztqtwnmfzh9))
This is no longer true
> BigQuery [doesn’t support column drop](https://stackoverflow.com/a/45822880) ([View Highlight](https://read.readwise.io/read/01gy2m00zzj33k4vvmt8gcf03v))