- Tags:: 🗃Archive, Data Team Vision And Mission, Data Culture
- Date:: 2021-06-19
Ejemplo de documento para el C-level de una compañía cuyo trabajo en Data Science normalmente se habrá iniciado solo con data scientists junior. El objetivo de este documento es visibilizar qué hace que no estén teniendo buenos resultados y pedir lo necesario para reconducir la situación.
Problemas
Un equipo “joven” de Data Science tiene unas carencias que dificultan implementaciones con éxito de productos data-intensive:
- Insuficiente fuerza de ingeniería.
- Inmadurez de los procesos de trabajo y comunicación.
- (Potencial) Falta de identificación de oportunidades a medio-largo plazo y company-wide de aplicación de Data Science.
Insuficiente fuerza de ingeniería
Casi cualquier solución que pueda proveer el equipo de Data Science va a requerir de un fuerte trabajo en ingeniería (Hidden Technical Debt In Machine Learning Systems):
El clasicazo de imagen con lo que supone poner un modelo de ML en producción:
🔗 to original context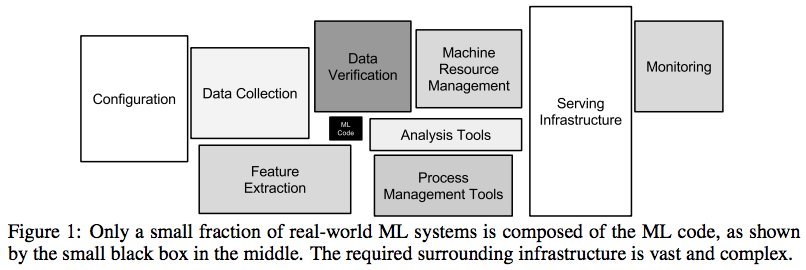
Sin embargo, dentro de que hay distintos perfiles bajo el término “Data Scientist”, algunos más generalistas, otros menos, ninguno comprende que se encarguen de todo:
There are some “full-stack” data scientists out there, but very few and far between (p. 58).
🔗 to original context
La manera en la que han atacado los problemas hasta ahora ha sido “tirar millas” por si mismos, desembocando en:
- Soluciones inefectivas: acabando algunas por ser rechazadas por los equipos en los que se iban a implementar.
- Fuerte deuda técnica en la infraestructura que han intentado construir para abstraer funcionalidad típica.
No han contado con mucho apoyo por parte de los equipos para los que iban a implementar una solución, en parte por no compartir objetivos, por incomodidad de los propios equipos (que creen que Machine Learning no es “su terreno”) y también por no existir comunicación efectiva por parte del equipo de Data Science.
Embeberlos en una vertical ataja parte del problema: los ingenieros de backend de la vertical pueden colaborar con Data Science en sus implementaciones y al estar en el marco de una vertical, asegurarse del alineamiento y priorización. Sin embargo:
- El equipo de Data Science es capaz de generar mucho más trabajo de implementación que el que el equipo de backend de una vertical puede absorber (si no se dedican recursos exclusivos para ello).
- El equipo de backend de una vertical puede no estar del todo en disposición de realizar una buena implementación, que podría requerir cierta especialización.
- También es necesario ir construyendo generalizaciones, abstracciones, servicios… en definitiva, una plataforma para eficientar el trabajo que Data Science hace (y que sería transversal a los equipos en los que estuvieran embebidos).
Por lo que esta estrategia sigue siendo insuficiente.
Inmadurez de los procesos de trabajo y comunicación
Los integrantes del equipo de Data Science son ambos relativamente juniors en el rol que ocupan hoy. La naturaleza del trabajo en Data Science es más extraña al resto de la compañía (es decir, comparado con ingeniería de software Hidden Technical Debt In Machine Learning Systems): hay una necesidad de comunicación estructurada mucho mayor, más esfuerzo necesario en monitorización (los errores no son tan evidentes), y muchas veces, lo tangible de su producción es conocimiento (a usar por Negocio). Por ello, las buenas prácticas, Definitions of Done, y cultura del equipo de Data Science están por determinar, no es suficiente con las definidas para ingeniería.
(Potencial) Falta de identificación de oportunidades a medio-largo plazo y company-wide de aplicación de Data Science
¿Quién recoge la responsabilidad de identificar en qué problemas hay una oportunidad de aplicar Data Science? (lo normal es que no haya CDO en esta etapa).
Soluciones propuestas
Insuficiente fuerza de ingeniería
Tradicionalmente, al equipo encargado de la fuerza de ingeniería relacionada con datos se le ha llamado Data Engineering:
Data Team Roles. (p. 91)
🔗 to original context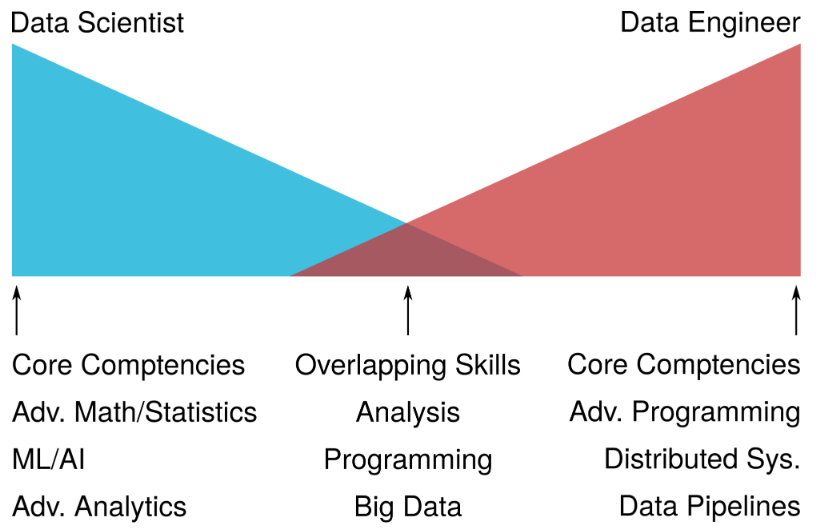
Dentro de Data Engineering también están surgiendo también distintas especializaciones dependiendo de las habilidades que se potencian de las de la figura superior, como Machine Learning Engineering (Data Teams, p. 91) o la más nueva Analytics Engineering, pero somos un equipo pequeño como para plantearlas (sí que será importante tenerlo en cuenta a la hora de describir las ofertas de trabajo que pudiéramos abrir).
Incluso fijando esta división de habilidades, hay distintas maneras de llevarla a la práctica. El objetivo a conseguir es que el equipo de Data Science sea capaz de tener ownership end-to-end de las soluciones que proponga. Por un lado, conseguiremos esto con componentes, servicios, patrones… reusables creados por Data Engineering, que Data Science utilizaría para construir sus soluciones (e.g., una manera escalable de computar y almacenar features para sus modelos de Machine Learning). Esta organización por la cual no hay handoffs entre Data Science y Data Engineering minimiza las fricciones y maximiza la autonomía (Engineers Shouldnt Write Etl).
Por otro lado, y especialmente mientras se van construyendo esas abstracciones, seguiríamos potenciando que la fuerza de ingeniería que necesitan la recibieran a través del equipo de ingeniería de la vertical en la que se encuentran, con apoyo de Data Engineering. La colaboración de Data Engineering podría ir desde una colaboración mínima en el diseño de la solución, hasta encargarse también de la implementación. Es decir, lo ideal es que las verticales estuvieran muy presentes en las implementaciones, pues serán los owners de las mismas (excepto en aspectos muy especializados), pero Data Engineering actuaría como un comando de ingeniería de respaldo para Data Science que impediría que éstos quedaran bloqueados.
Sin embargo, el equipo de Data Engineering tiene bastante trabajo por delante no solo para Data Science, sino de infraestructura básica para analítica. Estamos en un nivel bajo de la pirámide de necesidades de Data Science (The Ai Hierarchy Of Needs)
🔗 to original context
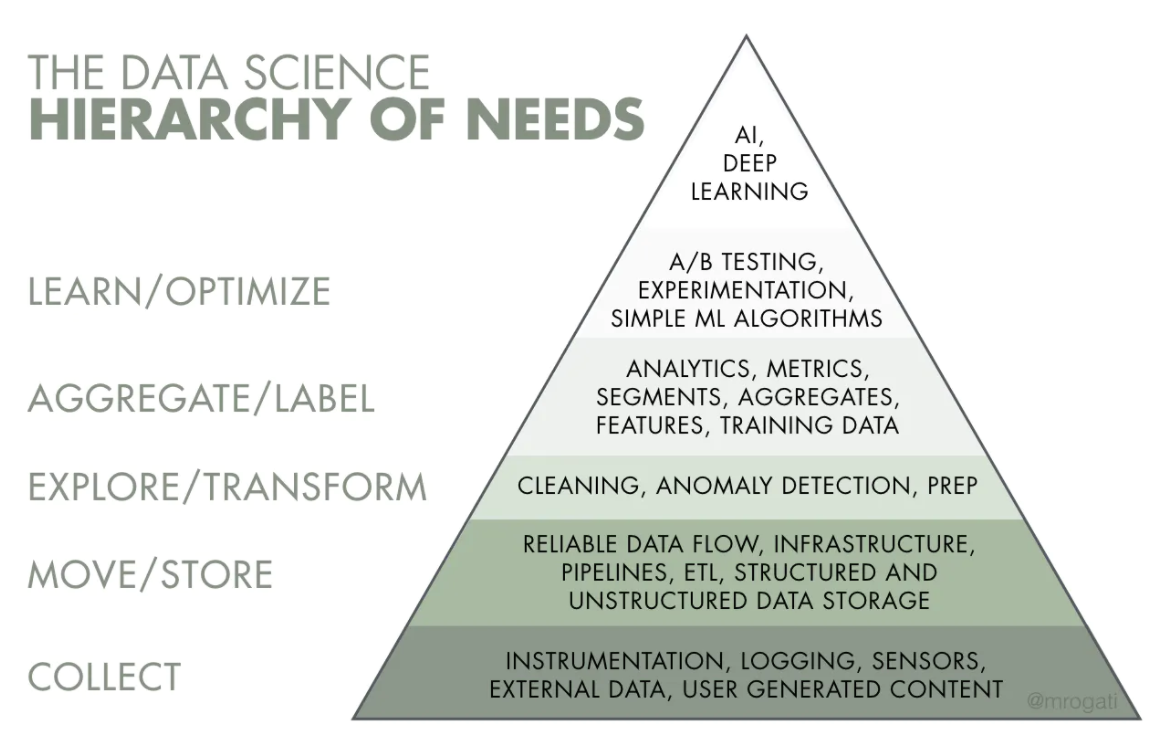
Tenemos mucho que resolver todavía, como se aprecia en nuestro roadmap tentativo:
[Imagen del roadmap]
Dado que el éxito de ambos equipos depende de que Data Engineering sea capaz de anticiparse (Engineers Shouldnt Write Etl) y que:
… you’ll need two to five data engineers for each data scientist. This ratio is so high because the 80 to 90 percent of the work for tasks fits into data engineering tasks rather than data science tasks (Data Teams, p. 98)
recomendaría entonces la contratación de un Data Engineer más en este momento, antes que añadir otro Data Scientist.
Aún así, buscaremos potenciar mejores prácticas de ingeniería por parte del equipo de Data Science: aunque reciban asistencia, es importante que tengan un buen conocimiento en este campo también a la hora de valorar las implicaciones de las distintas soluciones que pueden plantear a un problema de Data Science.
Inmadurez de los procesos de trabajo y comunicación
Aunque van mejor en este campo desde que están embebidos, el equipo de Data Science requiere de una supervisión más atenta que la que reciben hoy, que insista y asista en tener procesos de trabajo más estandarizados, comunicación estructurada, buenas prácticas para ir a producción, foco en la monitorización, hacer introspección en cómo pueden ser más ágiles…
Si los equipos de Data (Science & Engineering) tienen un manager exclusivo para ellos, podrá tener una mayor atención sobre esto, y considerando la evolución del equipo de Data Science, puede que sea suficiente.
Por otro lado, los PMs deben requerir un mayor esfuerzo por parte del equipo de Data Science en materia de comunicación. En la situación actual, los PMs intentan extraer información del equipo de una manera mucho más proactiva que lo que correspondería. El equipo de Data Science debería tener como uno de sus outcomes “conocimiento”, y que fuera fácil de consumir por el PM.
(Potencial) Falta de identificación de oportunidades a medio-largo plazo y company-wide de aplicación de Data Science
Idealmente, la identificación de los problemas y priorización debería seguir estando en manos de los PM, con información del equipo de Data Science. Cada PM debería mantener en su horizonte el Data Science como otra más de sus herramientas para alcanzar los objetivos de su vertical.
Además, podemos combinar este top-down approach con un bottom-up, dedicando el 20% del tiempo para investigación aplicada a problemas en cualquier lugar de la organización, fuera del marco del trabajo regular de una vertical.
Topología de los equipos
Teniendo en cuenta lo que hemos comentado y basándome en la taxonomía de equipos y sus relaciones de Team Topologies, propongo la siguiente organización:
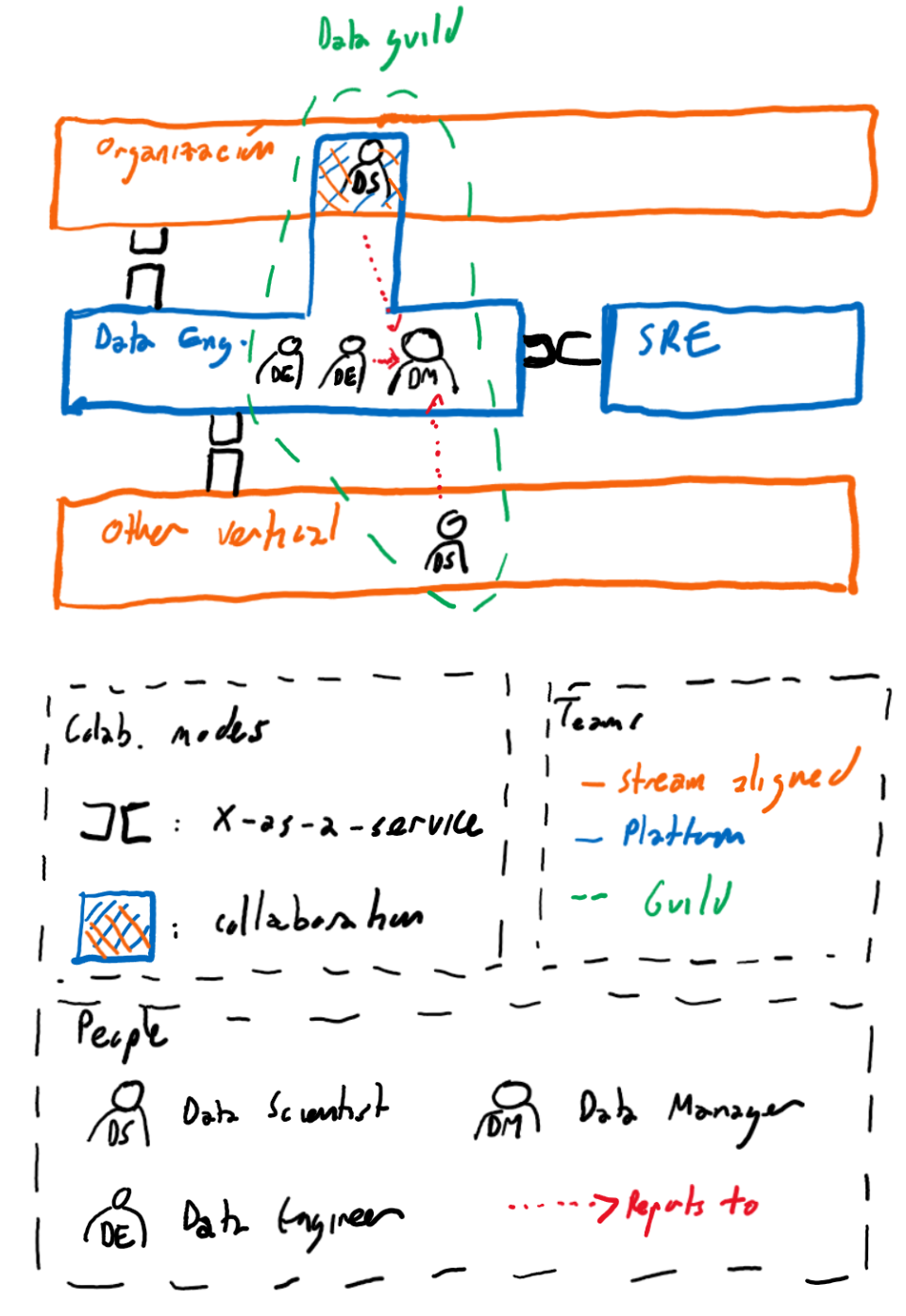
Relación Data Scientists - Data Scientists
A pesar de estar embebidos en distintas verticales, esperamos que los Data Scientists colaboraran intensivamente entre ellos (e.g., mediante Peer Review de sus análisis, reuniones semanales…), y formaran, junto con los Data Engineers, la guild de Data.
Como su estancia en los equipos no es permanente, tiene sentido que su management esté centralizado fuera de esos equipos, lo que es un modelo bastante popular (Data Teams, p. 156 “Embedding the Data Team in Business Unit”, Models for integrating data science teams within companies | by Pardis Noorzad | Medium, “The product data science model”, Building A Data Team At A A Mid Stage Startup Fig. 3 “Data team with decentralized backlog but centralized management”, The Care and Feeding of Data Scientists p. 6 “center-of-excellence model”) (see Data Team Topologies).
Nuevos Data Scientists pasarían por un período inicial de pairing para acabar embebidos en solitario en otra vertical.
Relación Data Scientists - Verticales (“Stream aligned” teams)
Cada data scientist estaría embebido en una vertical, en plazos más o menos largos (mínimo dos Q), con el objetivo de que puedan empaparse del dominio del problema de una vertical y así no solo poder iterar convenientemente sus soluciones, si no proponer mejoras más transformativas.
Esto no quita para que puedan realizar mantenimiento para otros equipos si fuera necesario.
Podemos valorar si tiene sentido tener a más de un Data Scientist en una vertical (si en una vertical hubiera mucho trabajo en la parte de “Science”), pero como hemos mencionado antes, en general la mayor parte de las tareas de Data Science son de ingeniería, no de analísis o modelado.
Relación Data Scientists - Data Engineering
El objetivo es conseguir darles una serie de abstracciones (servicios, plataformas, buenas prácticas) tal que los Data Scientists sean capaz de construir sus soluciones end-to-end por si mismos. Hasta que lleguemos a eso y en integraciones particularmente complicadas, los Data Engineers colaboraríamos en las implementaciones de los Data Scientists de manera directa, al tiempo que construimos abstracciones, así como atenderíamos a las necesidades de datos del resto de la organización.
Relación Data Engineering - SRE
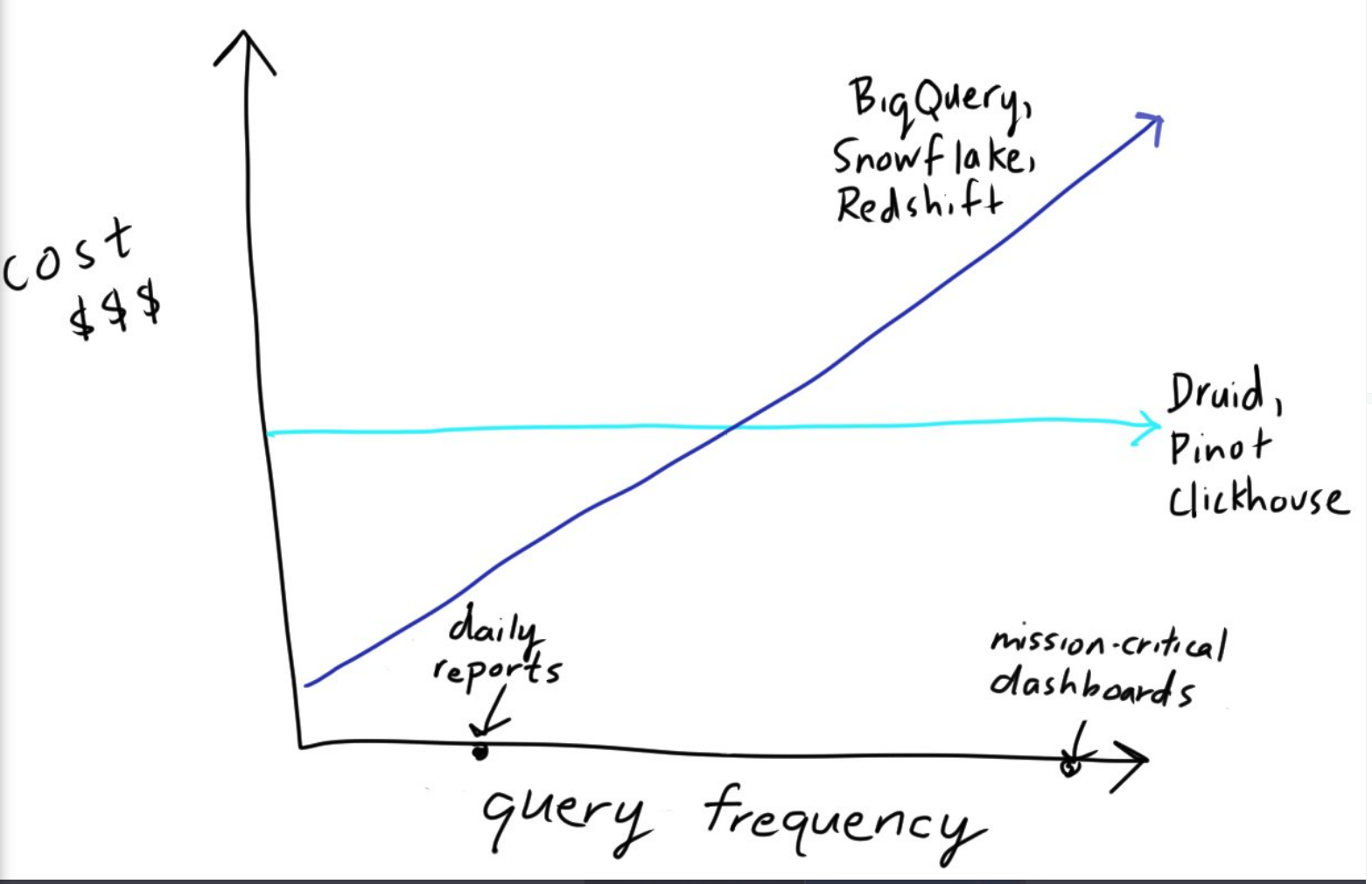
En el futuro cercano, por agilidad, apostaremos por el Modern Data Stack y servicios “managed” en lo posible, con lo que la relación de Data Engineering con SRE puede ser muy parecida a la de SRE con el resto de verticales. Sin embargo, es posible que nos tengamos que replantear esta estrategia más adelante, por sus costes (The Two Philosophies of Cost in Data Analytics). From The Cost Of Cloud A Trillion Dollar Paradox:
🔗 to original contextYou’re crazy if you don’t start in the cloud; you’re crazy if you stay on it
O según este tweet:
Si introdujeramos infraestructura propia, tendría sentido ser también responsables de mantenerla viva:
The same team is responsible for both the data pipeline code and keeping it running. This method is chosen to prevent the quintessential “throw it over the fence” problems that have long existed between developers and operations staff where developers create code of questionable quality that the operations team is forced to deal with the problems (p. 15)
🔗 to original context
Next steps
Here there would be a concrete sequence of steps to tackle all this.